本文将建模参与者简单划分为技术方(IT)和业务方,由于内容上主要针对的对象是业务方,因此整体上行文和用词倾向于用业务可接受的逻辑和语言,并且算法相关的内容也简化了许多。
一、什么是模型? 🔗
若业务方与IT一起合作建模型,业务方需要对模型涉及的概念有怎样的了解?
1.1.什么是模型? 🔗
模型是针对不同的业务目标、选择合适的方法来求解(答案),一般可用来分析、挖掘或预测,是为不确定性作确定性度量。模型输出的结果一般是提供决策依据而不是决策本身。
实际业务中使用的模型,从实现方式上可分为两个大类:
-
规则类模型:搜集数据,梳理业务,人为定义因子和标准,人为制定规则
-
算法类模型:搜集数据,梳理业务,人为定义因子、调试算法,机器计算出规则
| 规则类 | 算法类 |
|---|---|
|
|
| 人指定规则 | 人指定学习方法,机器自动学习得到规则 |
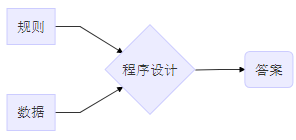
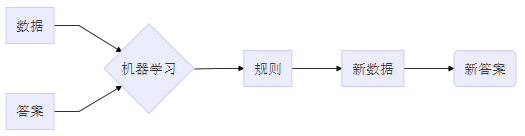
1.1.1.规则类模型 🔗
实际业务中应用的规则类模型一般要复杂得多,此处为了便于说明进行简化举例。假设业务方需要做一个简单的预警,以下三个因子可满足预警的要求,通过这三个因子可搭建一个规则类模型。
| - | 因子含义 | 基础标准 | 方式1-因子占比 | 方式2-因子占比 |
|---|---|---|---|---|
| 因子1 | 是否…… | 是 | 100% | 30% |
| 因子2 | ……件数 | >=3 | 100% | 40% |
| 因子3 | ……件数 | >=3 | 100% | 30% |
常见方式有两种:
-
方式1:选出因子,给每个因子定个标准,单个因子超过标准则预警。此例子中模型有三条规则:因子1为是则预警;因子2件数>=3则预警;因子3件数>=3则预警。
-
方式2:给每个因子设置一个占比,所有因子乘以因子占比后加起来超过一个整体标准则预警。此例子中,假如设定整体标准为超过60%,模型仅1条规则,例如’因子1为否’+‘因子2件数>=3’+‘因子3件数>=3’=70%可预警。
这两种方式并无绝对的优劣之分,只是应用的场景不同。例如方式1,因子的含义足够复杂且单个因子之间毫不相关,业务上确定只需要单个因子超标就预警;方式二,因子的含义相对简单,且大量存在多个因子都超标的情况,那么就多个因子组合起来超过一个整体标准才预警。
常见误区有两种:
-
误区1:比如为了抓坏样本时,建模只看坏样本数据。抓坏样本应该是看坏样本与好样本的区别,应着重找出坏样本不同于好样本的地方,而不仅仅只是看坏样本自身的特点。
-
误区2:缺少可以量化的、用于评价模型效果的指标。规则制定好了以后一定要同时制定出针对模型效果的评价指标,这既是监测维护模型的根本,也是调优的基础。
遇到复杂的问题时可以不断增加新的规则去解决,但积累越来越多的规则一定是最好的解决方法吗?
1.1.2.算法类模型 🔗
在建立算法类模型的过程中,许多由人来决策的步骤通常会更依赖由算法来提供决策依据。为了便于说明和对比,将建模步骤简化如下:~圆圈是需要业务方深度参与,方框是需要IT深度参与~

-
设定目标:建立模型通常要设定明确、合理的目标,即评价模型好坏的具体指标,达标才能正式上线投产,后续监测维护也有方向。
-
选因子:比如业务方搜集了一百个因子,运用算法来计算出每个因子影响结果的重要性大小,选出最重要的因子。
-
用因子:如前面例子中将“因子2件数”的标准定为“>=3”,在此步骤中可能会将“因子2件数”拆分成“小于3”、“3-5”、“大于5”等多种情况,具体怎么用因子也可以让算法来提供依据。
-
评价模型好坏:可以直接用算法的评价指标,也可以根据业务情况来定。
1.1.3.规则类模型VS.算法类模型 🔗
-
两者都会遇到的问题:
-
影响结果的因素始终在变化
-
数据本身在不断变化
-
-
两者没有绝对优劣之分,但应用的场景一定不同:
| - | 规则类模型 | 算法类模型 |
|---|---|---|
| 可解释性 | 模型本身完全可以解释,给业务人员使用或者向领导汇报都容易 | 除了回归类算法建立的模型以外,模型本身大多难以解释,需从外部解释 |
| 复杂度 | 有限 | 无限 |
| 耗时 | 快,指标或因子选好后,模型基本成型 | 慢,选因子、用因子、选算法、调优参数都费时间 |
| 可扩展性 | 某次指标模型测算仅针对某一个时点 | 后台计算框架搭好可反复使用,满足某些条件时模型可迁移 |
正是因为实际业务是一直在变的,所以建模绝对不是一劳永逸的,不管是建立规则类模型还是算法类模型,后续都要跟踪维护,才能保证模型的效果维持稳定。
1.2.什么是特征? 🔗
特征,在不同领域有不同的名称,有叫“变量”,有叫“指标”,也有叫“因子”。特征工程就是一个把原始数据转变成特征的过程,这些特征可以很好的描述这些数据,并且利用它们建立的模型在未知数据上的表现性能可以达到最优(或者接近最佳性能)。
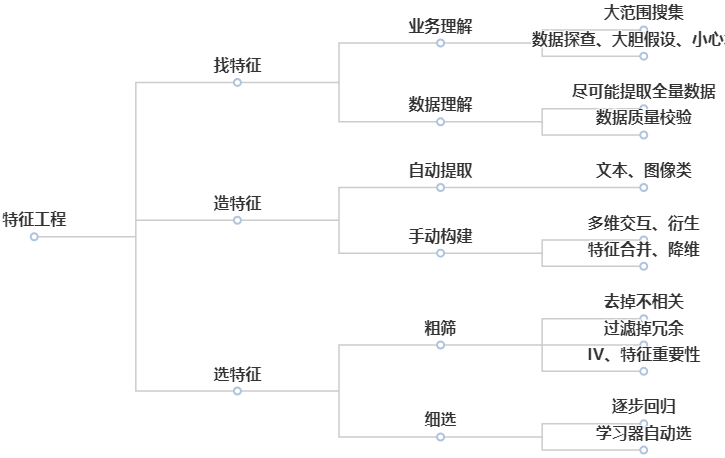
-
大范围搜集:尽可能找出所有对结果有影响的因素
-
数据质量校验:主要是梳理清楚数据是从哪来的,怎么来的,弄清楚数据稀疏、缺失、不完整等情况,有没有意外的IT问题导致的数据错误,这一步是防止潜在的严重问题。
-
多维交互、衍生:数据的类型分三种:类别型(如购买动机为本人、为子女、为配偶)、数值型(如商品件数、购买金额)、时间(如时间点、时间间隔、频次)。交互就是如客户为本人购买件数,客户为本人购买间隔天数,客户为本人在某段时间内购买的频次;衍生,就是再加上最大值、最小值、求和、平均等,比如客户为本人购买商品金额的均值。
-
特征合并、降维:比如PCA(主成分分析)/LDA(线性判别分析),一般不用。
-
去掉不相关:去掉对结果没有影响或影响极小的特征。
-
过滤掉冗余:同时存在多个特征对结果有一样的影响,只留一个
-
逐步回归:把特征一个一个放到模型里,每增加一个就评估下有没有提升整体效果,有就留下,没有就去掉,直到选出最佳的特征子集。
-
学习器自动选:相当于预建模,就是字面含义自动选。
1.3.什么是算法?(大方向)怎样选择合适的算法? 🔗
算法就是用于求解的计算方法,比如1+1=2,这里的加法可看作求精确解的算法。又如要根据一个人的身高、体重、爱好等预测性别,用逻辑回归预测此人有70%概率是男性,用随机森林预测此人有80%概率是男性,这就是用不同的分类算法求近似解。
在机器学习这个大的领域中有相当多的分支,专门用来处理不同的情况:
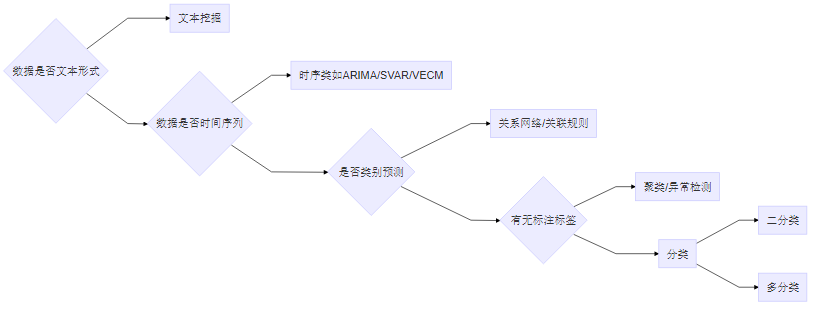
-
涉及文字、语音、图像识别的需运用深度学习算法;
-
若包含文本,需运用文本挖掘类算法;
-
若是时间序列类数据,运用时序类算法;
-
若非类别预测,而是如寻找事物之间的关系或关联,需运用关系网络或关联规则类算法;
-
有无标注标签:标签:就是历史已有或未来待预测的结果。用有标签的数据建模就从有监督算法中选,常见的有逻辑回归、决策树、XGBoost等;用无标签的数据建模就从无监督算法中选,常见的有各种聚类、异常检测。有监督与无监督最大的区别是,在机器自动学习的过程中,有无使用标签来判定学习效果。
-
聚类,即“物以类聚、人以群分”,通常通过计算样本之间的距离来判定样本的类别,距离越近的聚为一类,最终聚类簇内部距离最小而簇与簇之间距离最大时聚类完成。
-
分类,通常有二分类、多分类两种。二分类即所需分类的类别只有两个,比如性别只分男、女,有无欺诈只分有欺诈、无欺诈。多分类即所需分类的类别有多个,比如年龄可分为青年、中年、老年等等。
1.4.怎样选择合适的算法? 🔗
业务中应用的模型最常见的是二分类问题,以此为例。
-
综合考量三点:
- 数据量:数据量较少时,不要用复杂度太高的算法;
- 好坏样本比例:好坏样本比例越均衡,问题越容易,比例越不均衡,问题越难。
- 可解释性:只有回归类的算法建立的模型本身可以解释。
-
分类算法优缺点:
- 逻辑回归:可解释性最好,模型可以转换为规则,复杂度最低、效果最差;
- XGBoost:模型本身不可解释,复杂度最高、效果最好
-
具体怎样选:
- 若是要求模型本身可解释,就只能选逻辑回归。
- 若是不要求模型本身可解释且数据量不少的话,直接用XGBoost,再搭配一些机器学习可解释算法如LIME,从外部解释模型。
- 若是不要求模型本身可解释且数据量少的话,就将传统分类算法挨个试一遍,选效果最好的用。
二、怎样建立模型? 🔗
以业务场景中的模型应用为例,哪些步骤需要IT完成、哪些步骤需要业务方完成
2.0. 制定明确、合理的目标 🔗
在正式建模型之前,一定要充分了解业务现状和数据情况,制定出明确、合理的目标。例如:要预测某项业务中可能出现的坏样本,那么整个建模目标就需要细化出以下几点:
-
1.给坏样本具体的定义。
-
2.明确数据的范围和具体维度:
- 维度:区分清楚要建模的具体维度是到商品维度、客户维度,还是销售人员维度、事件维度。
- 范围:区分清楚所要预测的业务时点,假如做投诉预警,那么明确是在客户购买的时点预警,还是销售人员离职前的时点预警,或是客户电话投诉的时点预警。
-
3.了解建模的难度:坏样本占总体样本比例为1/2、1/10、 1/100、 1/1000时,坏样本占比越低,建模越难。
-
4.衡量可以接受的阈值:假如确定好了对客户维度进行预警,模型给每个客户进行评分,评分高的需要被抓出来,那么评分高于多少才是“高”?一般可以定一个阈值,高于阈值的即评分高,要被当做坏样本抓出来。定前0.5%?前3%?前10%?阈值太高,被预警的量会太少;阈值太低,被预警的量太多,又会对业务方造成压力。
-
5.确定模型目标:究竟是更想要在确定的阈值范围内尽可能抓出更多坏样本(精确率),还是更想要从所有坏样本中尽可能找出更多坏样本(召回率)?是否需要明晰出模型内部运行的具体规则?
-
6.明确模型预测结果的具体应用场景:预测结果如何追踪验证?预测究竟是为降低某项成本还是提高某种效率?
2.0.1. 精确率/召回率 🔗
| - | 实际坏样本 | 实际好样本 | - |
|---|---|---|---|
| 预测坏样本 | 120 | 120 | 240 |
| 预测好样本 | 80 | 680 | 760 |
| - | 200 | 800 | 1000 |
-
精确率:
- = 120/240 = 50%
- 预测坏样本且实际坏样本数(120) / 预测坏样本总数(240)
- 精确率越高,表示对坏样本抓得越准
-
召回率:
- = 120/200 = 60%
- 预测坏样本且实际坏样本数(120) / 实际坏样本总数(200)
- 召回率越高,表示对坏样本抓得越全
2.0.2. 验证目标的常见误区 🔗
假如(2.0.1)中的图是建模时设定的目标,而下图是建模完成后验证是否达标。
| - | 实际坏样本 | 实际好样本 | - |
|---|---|---|---|
| 预测坏样本 | 7000 | 4500 | 11500 |
| 预测好样本 | 3000 | 5500 | 8500 |
| - | 10000 | 10000 | 20000 |
-
目标精确率为50%,验证精确率:7000/11500 = 60.86%,达标。
-
目标召回率为60%,验证召回率:7000/10000 = 70%,达标。
但实际上并未达标,因为有以下两个误区:
-
误区1:设定目标时好坏样本比例为800:200=4:1,验证时好坏样本比例换成10000:10000=1:1,这是降低验证难度,最终实际应用时模型效果依然不会达标。
-
误区2:设定目标时预测坏样本的比例为240/1000=24%,验证时预测坏样本的比例换成11500/20000=57.5%,这也是降低验证难度。
2.1.基本建模流程 🔗
图中圆圈标记的需要业务方深度参与的,方框标记的需要IT深度参与
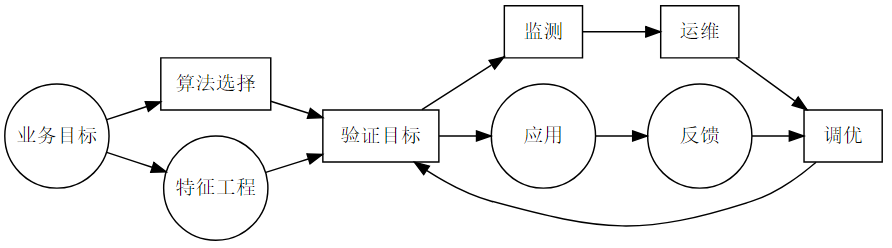
-
业务目标
- 收集因子,确定数据范围,给出标签的具体定义
- 根据实际业务情况来制定目标,设定具体的召回率、精确率目标
- 阈值范围代表需要付出的用于验证结果的成本
-
算法选择
- 好坏样本比例,样本类别不平衡
- 可解释性
-
特征工程
- 根据业务逻辑搜集因子
- 离散化处理(用因子),筛选关键因子
-
应用维护
- 好坏样本比例变了
- 某些重要特征的重要性降低了
2.2.应用案例 🔗
(同一个特征,离散化处理不一样最终对结果的影响程度也会不一样,缺失) (模型分层与融合,缺失)
2.3.XGBoost+LIME 🔗
(运用LIME算法可以展示出,每个样本的结果具体受到哪些特征的影响、是正影响还是负影响、影响程度多大等等,缺失)
三、建好的模型应该怎么用? 🔗
3.1.模型预测的结果应该怎么使用? 🔗
实际应用时,模型提供的是决策依据而不是决策本身,预测的结果最终应融入业务中。
(缺失)
3.2.模型的验证成本 🔗
(缺失)
3.3.关于建模型的几点建议 🔗
-
建议1:简单问题不需要建复杂模型来解决
-
可以用简单方法解决的问题,不需要建模型
-
业务形式或规则固定、能直接用运营手段干预解决的问题,不需要建模型
-
-
建议2:正式建模之前的探索性数据分析很重要
-
详细的数据探查很重要,建模型需要数据,缺少数据或者数据质量太差难以建成好用的模型
-
指标搜集尽可能全面,不要遗漏特征,若要最终效果符合预期,影响最终结果的因素需包含在数据中
-
-
建议3:模型建立完成后,需追踪效果
-
定期人工或自动化监测应用效果,例如每天、每月、每季度、每半年
-
周期性重新训练模型,例如每一年或每两年
-
-
建议4:不要为了建模而建模、为了预测而预测
-
模型一定要与业务结合才能起作用,要明确模型解决的是什么问题
-
建模前一定要先梳理清楚具体目标、怎么使用、后续如何监测、以及何种情况需要改进
-